Java语言
1. 语言基础
1.1 基础语法
- 数据类型
数据类型分为两类:基本数据类型、引用数据类型。
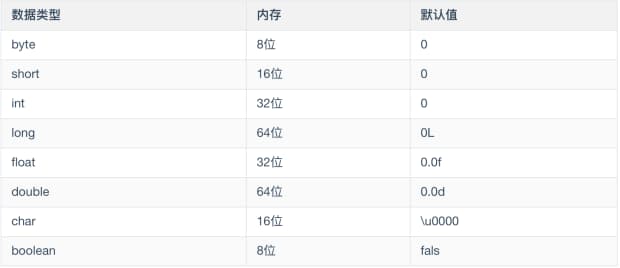
1 | Java中的基本数据类型只有**四类八种** |
- 浮点型
1 | 浮点型有两种:float、double |
- 字符型
1 | 字符型为char,char类型是一个单一的16位Unicode字符。 |
- 布尔型
1 | The boolean data type has only two possible values: true and false. Use this data type for simple flags that track true/false conditions. This data type represents one bit of information, but its "size" isn't something that's precisely defined. |
- 引用数据类型
1 | 只要不是基本数据类型就是引用数据类型。 |
- 自动类型转换(隐式)
1 | 转换规则: 数据范围必须是**从小到大**,即由小的转换成大的,自动转换。 |
- 强制类型转换(显式)
1 | 注意事项: |
- 运算符的优先级
1 | 单目(一元)>算术运算符>移位>关系>位>条件(三元)>赋值 |
- 基础语法
1 | 1. 大小写敏感: Java是大小写敏感的语言,例如Hello和hello是不同的,这其实就是Java的字符串表示方式。 |
- 方法
- 构造方法
1 | 作用:用来创建对象的 |
- 静态方法
1 | 静态方法又叫类方法。 |
- 非静态方法(成员方法)
1 | 方法之间的调用注意事项: |
- 方法重载
1 | 多个方法的名称相同,但是参数列表不一样。 |
- 参数传递机制
1 | Java的参数传递机制都是:值传递 |
- 数组
1 | Java的内存划分成为5个部分: |
1.2 面向对象
- 特点
1 | 面向对象思想是一种更符合我们思考习惯的思想,它可以将复杂的事情简单化,并将我们从执行者变成指挥者。 |
面向对象语言包含三大基本特征:
-
封装
就是将一些细节信息隐藏起来,对外界不可见。
- 方法就是一种封装
- private关键字也是一种封装
一旦使用private进行修饰,那么本类当中仍然可以随意访问,但是超出了本类范围之外就不能再直接访问了。
可以使用getter/setter方法间接访问private成员变量。
-
继承
继承是多态的前提,如果没有继承,就没有多态。
继承主要解决的问题就是:共性抽取
**变量重名的解决方法**
局部变量: 直接写成员变量名
本类的成员变量: this.成员变量名
父类的成员变量: super.成员变量名
**重写(override)**
概念:在继承关系中,方法的名称一样,参数列表一样。
方法重写(override):方法名称一样,参数列表也一样。(覆盖重写)
方法重载(overload):方法名称一样,参数列表不一样。
**覆盖重写的注意事项:**
1. 必须保证父子类之间的方法名称相同,参数列表也相同。
2. 子类方法的权限必须大于等于父类方法的权限修饰符。
public>protected>(default)>private
备注:(default)不是关键字default,而是什么修饰符也不用。
继承关系中,父子类构造方法的访问特点:
1. super的父类构造调用,必须是子类构造方法的第一个语句。不能一个子类构造调用多次super构造
注意事项:
子类必须调用父类构造方法,不写则默认super(),写了则用写的指定的super调用,super只能有一个,还必须是第一个。
Java继承的三大特点
- Java语言是单继承的,即一个类的直接父类只能有唯一一个。
- Java语言可以多级继承。
- 一个子类只能有一个父类,但是一个父类可以有多个子类。
如果父类当中的方法不确定如何进行{}方法体实现,那么这就应该是一个抽象方法。
抽象类:抽象方法所在的类必须是抽象类才行。在class之前写上abstract即可。
1 | public abstract class Animal{ |
如何使用抽象类和抽象方法
-
不能直接创建new抽象类对象
-
必须用一个子类来继承抽象父类。
-
子类必须覆盖重写抽象父类当中的所有抽象方法。
覆盖重写(实现):子类去掉抽象方法的abstract关键字,然后补上方法体大括号
- 创建子类对象进行使用。
1
2
3
4
5
6public class Cat extends Animal{
public void eat(){
}
}
- 多态
一个对象拥有多种形态,这个就叫对象的多态性。
代码当中体现多态性,其实就是一句话,父类引用指向子类对象。
格式:
父类名称 对象名 = new 子类名称();
或者
接口名称 对象名 = new 实现类名称();
访问成员变量和方法的规则:
访问成员方法:等号右边new的谁,优先用谁,没有则向上找。
直接通过对象名称访问成员变量:等号左边是谁,优先用谁,没有则向上找。
间接通过成员方法访问成员变量:看该方法属于谁,优先用谁,没有则向上找。
对象的转型
- 对象的向上转型,其实就是多态写法:
格式:父类名称 对象名 = new 子类名称();
- 对象的向下转型,其实是一个【还原】的动作
格式:子类名称 对象名 = (子类名称) 父类对象
注意事项:
- 必须保证对象本来创建的时候就是A,才能向下转型成为A。
- 如果创建的对象本来不是A,非要向下转型为A就会报错。
四种权限修饰符
内部类
- 成员内部类
- 局部内部类(包含匿名内部类)
成员内部类的定义格式:
1 | 修饰符 class 外部类名称{ |
局部内部类的定义格式:
1 | 修饰符 class 外部类名称{ |
匿名内部类的定义格式:
1 | 接口名称 对象名称 = new 接口名称(){ |
- 类和对象
什么是类
- 类:是一组相关属性和行为的集合。
现实中,描述一类事物:
-
属性:就是该事物的特征信息。(是什么)(成员变量)
-
行为:就是该事物能够做什么。(成员方法)成员方法不要写static关键字。
什么是对象
- 对象:是一类事物的具体体香。对象是类的一个实例。
类与对象的关系
- 类是对一类事物的描述,是抽象的。
- 对象是一类事物的实例,是具体的。
- 类是对象的模板,对象是类的实体。
成员变量和局部变量的区别
1 | 1. 定义的位置不一样 |
- 对象数组
数组有一个缺点:一旦创建,程序运行期间长度不可以发生改变。
- 字符串
1 | 1. 字符串的内容不可变 |
StringBuilder类:字符串缓冲区,可以提高字符串的效率
常用方法:
append
toString
- 静态关键字static
一旦用了static关键字,那么这样的内容不再属于对象自己,
而是属于类的,所以凡是本类的对象,都共享同一份。
1 | 一旦使用static修饰成员方法,那么就成为了静态方法,静态方法不属于对象,而是属于类的。 |
静态代码块
特点:当第一次用到本类时,静态代码块执行唯一的一次。
静态内容总是优先于非静态,所以静态代码块比构造方法先执行。
静态代码块的用途:
用来一次性的对静态成员变量进行赋值。
Arrays工具类
toString(数组):将参数数组变成字符串(按照默认格式:[元素1,元素2,…])
1.3 接口
接口就是多个类的公共规范
接口是一种引用数据类型,最重要的内容就是其中的:抽象方法。
从Java 8开始,接口 里允许定义默认方法。
备注:接口当中的默认方法可以解决接口升级的问题。
什么是接口升级?
就是已经投入使用的接口,想在其中添加新的方法,这时如果直接添加,会导致所有实现该接口的类报错,但是使用default默认方法可以解决此问题,并且该方法也可以被其他接口实现类覆盖重写。
格式:
1 | public default 返回值类型 方法名称(参数列表){ |
从Java 9 开始,接口中允许定义私有方法。
- 普通私有方法,解决多个默认方法之间的重复代码问题
格式:
1 | private 返回值类型 方法名称(参数列表){ |
- 静态私有方法:解决多个静态方法之间重复代码问题
格式:
1 | private static 返回值类型 方法名称(参数列表){ |
接口与接口之间是多继承的。
- 日期时间类
date
- DateFormat类
日期时间格式化类
- 包装类
1 | 基本类型 对应的包装类 |
装箱与拆箱
装箱:从基本类型转换成对应的包装类对象
拆箱:从包装类对象转换为对应的基本类型
1 | Integer i= Integer.valueOf(4)//装箱 |
1.4 容器
- collection集合
**集合:**集合是Java中提供的一种容器,可以用来存储多个数据。
集合和数组既然都是容器,它们有啥区别?
- 数组的长度是固定的,集合的长度是可变的
- 数组中存储的是同一类型的元素,可以存储基本数据类型值。集合存储的都是对象,而且对象的类型可以不一致。在开发中一般当对象多的时候,使用集合进行存储。
常用共性方法
1 | public boolean add(E e): 添加对象 |
List
- 有序的集合(存储和取出元素顺序相同)
- 允许存储重复的元素
- 有索引,可以使用普通的for循环遍历
- ArrayList(查询快,增删慢)
1 | ArrayList<E> list = new ArrayList<>(); |
常用方法:
add,get,remove,size
- LinkedList(查询慢,增删快)
1 | LinkedList<E> linked = new LinkerdList<>(); |
Set
- 不允许存储重复的元素
- 没有索引
- HashSet
1 | HashSet<E> set = new HashSet<>(); |
- 是一个无序集合
- 底层是一个哈希表结构
哈希值:是一个十进制的整数,由系统随机给出(就是对象的地址值,是一个逻辑i地址,是模拟出来的地址,不是数据实际存储的物理地址)
1 | int hashCode():获取对象的哈希码值 |
哈希表(查询快)
哈希表的结构,jdk1.8之后:
- 哈希表=数组+链表;
- 哈希表=数组+红黑树;
- LInkedHashSet
LInkedHashSet特点:
底层是一个哈希表+链表,多了一条链表(记录元素的存储顺序),保证元素有序。
HashSet存储自定义类型元素
给HashSet中存放自定义类型元素时,需要重写对象中的hashCode和equals方法,建立自己的比较方式,才能保证HashSet集合中的对象唯一。
可变参数
格式
1 | 修饰符 返回值类型 方法名(数据类型...变量名){ |
Map
特点
- map集合是一个双列集合,一个元素包含两个值(key:value)
- map集合中的元素,key和value的数据类型可以相同,也可以不同
- map中key是不允许重复的,value可以重复
- map中的key和value一一对应
- HashMap(初始长度16)
特点:
- HashMap集合底层是哈希表:查询速度特别快
- hashMap是一个无序集合,存储和取出元素的顺序可能不一致
- LinkedHashMap
特点:
- 底层是哈希表+链表(保证迭代的顺序)
- 是一个有序的集合,存储和取出元素的顺序是一致的
- TreeMap
1 |
Collections工具类
常用方法
1 | public static <T> boolean addAll(Collection<? super T> c, T... elements) :往集合中添加一些元素 |
1.4.1 Iterator迭代器
迭代:Collection集合元素的通用获取方式。
迭代器的使用案例
1 | public static void main(String[] args) { |
1.5 异常
异常:指的是程序在执行过程中,出现非正常的情况,最终导致JVM非正常停止。
Java处理异常的方式是中断处理。
异常产生的过程解析
1.5.1 异常的处理
Java异常处理的五个关键字:try、catch、finally、throw、throws
- 抛出异常throw
throw作用:
可以使用throw关键字在指定的方法中抛出指定的异常
使用格式:
throw new xxxException(“异常产生的原因”);
注意:
- throw关键字必须写在方法的内部
- throw后面new的对象必须是Exception或者Exception的子类对象
- throw抛出指定的异常对象,我们必须处理这个异常对象,要么用throws,要么try…catch
1 | 以后(工作中)我们首先必须对方法传递过来的参数进行合法性校验 |
- 声明异常throws(异常处理的第一种方式)
作用:
当方法内部抛出异常对象的时候,那么我们就必须处理这个异常对象
可以使用throws处理异常对象,把异常声明抛出给方法的调用者处理(自己不处理,谁调用我让谁处理),最终交给jvm处理–>中断异常
使用格式:在方法声明时使用
1 | 修饰符 返回值类型 方法名(参数列表) throws xxxException,.....{ |
- 捕获异常try…catch(异常处理的第二种方式)
格式:
1 | try{ |
1.6 泛型
泛型是一种未知的数据类型,当我们不知道使用什么数据类型的时候,可以使用泛型。
泛型的数据类型在创建对象的时候确定
创建集合对象,使用泛型
好处:
- 避免了类型转换的麻烦,存储的是什么类型,取出的就是什么类型
- 把运行期异常(代码运行之后抛出的异常)提升到了编译期
弊端:
- 泛型是什么类型,只能存储什么类型的数据
含有泛型的方法
定义格式
1 | 修饰符 <泛型> 返回值类型 方法名(参数列表(使用泛型)){ |
含有泛型的接口
定义格式
1 | 第一种使用方式,定义接口的实现类,实现接口并指定接口的泛型 |
泛型通配符
?:代表任意的数据类型
使用方式:
不能创建对象使用
只能作为方法的参数使用
高级使用-受限泛型(要求只要看源码能看懂就行)
作用:限定数据的使用类型。
泛型的上限限定:?extends E 代表使用的泛型只能是E类型的子类/本身
泛型的下限限定:?super E 代表使用的泛型只能是E类型的父类/本身
- 数据结构
红黑树
特点:
- 趋近于平衡树,查询的速度非常快,查询叶子节点最大次数和最小次数不能超过2倍
约束:
- 节点可以是红色或者黑色
- 根节点是黑色
- 叶子节点(空节点)是黑色
- 每个红色的节点的子节点都是黑色
- 任何一个节点到其每一个叶子节点所有路径上的黑色节点数相等
1.7 反射
作用
- 基本作用:可以得到一个类的全部成分然后操作
- 可以破坏封装性
- 最重要的用途是:适合做Java的框架,基本上,主流的框架都会基于反射设计出一些通用的功能。
1.8 注解
就是Java的特殊标记,作用是:让其他程序根据注解信息来决定怎么执行该程序
特殊属性名:value
如果注解只有一个value属性,使用注解时,value名称可以不写。
元注解
修饰注解的注解
常见的元注解
1 | 1. |
注解的解析
要解析谁上面的注解,就先拿到谁
1.9 I/O
重点:记住三个单词
file: 文件
directory:文件夹/目录
path: 路径
递归:指在当前方法内部调用自己的这种现象
递归的分类:
- 直接递归
方法自身调用自身
- 间接递归
A方法调用B方法,B方法调用C方法,C方法调用A方法。
Java中的I/O操作主要是指使用Java.io包下的内容,进行输入、输出操作。
- 字节流(InputStream/OutputStream)
1 | FileInputStream |
使用字节流读取中文文件容易产生乱码
一个中文
GBK: 占用两个字节
UTF-8:占用三个字节
- 字符流(reader/writer)
作用:读取字符信息,一次读取一个字符
jdk7的新特性
在try后边可以增加一个(),在括号中可以定义流对象
那么这个流对象的作用域就在try中有效
try中的代码执行完毕会自动把流对象释放,不用写finally
格式
1 | try(定义流对象;定义流对象...){ |
- 缓冲流
作用:提高文件读写的效率
字节缓冲流(BufferedInputStream & BufferedOutputStream)
字符缓冲流(BufferedReader & BufferWriter)
- 转换流(OutputStreamWriter & InputStreamReader)
作用:能够转换编码
- 序列化流(ObjectOutputStream & ObjectInputStream )
作用:能够持久化存储对象
1 | Serializable 接口也叫标记型接口 |
序列化集合
当我们想在文件中保存多个对象的时候,可以把多个对象存储到一个集合中,然后对集合进行序列化和反序列化。
2. JVM
2.1 类加载机制
2.2 字节码执行机制
2.3 jvm内存模型
2.4 gc垃圾回收机制
2.5 jvm性能监控和故障定位
2.6 jvm调优
3. 并发/多线程
3.1 并发编程
3.2 多线程
创建线程的步骤:
- 声明Thread类的子类
- 重写Thread类的run方法
1 | 实例 |
Thread类中的常用方法
1 | public final String getName():获取;当前线程名 |
并发与并行
并发:指两个或多个事件在同一时间段内发生
并行:指两个或多个事件在同一时刻发生(同时发生)
线程与进程
进程: 是指一个内存中运行的应用程序
线程: 是指进程中的一个执行单元,负责当前进程中程序的执行,一个进程至少有一个线程。一个进程中是可以有多个线程的,这个应用程序称为多线程程序。
线程调度
分时调度: 所有线程轮流使用CPU的使用权,平均分配每个线程占用CPU的时间。
抢占式调度: 优先让优先级高的线程使用CPU,如果线程的优先级相同,那么会随机选择一个(线程随机性),Java使用的为抢占式调度。
3.2.1 线程安全
解决线程安全问题
- 同步代码块: synchronized 关键字可以用于方法中的某个区块中,表示只对这个区块的资源实行互斥访问。
使用synchronized关键字容易产生死锁(如何解决,在后续内容中写)
格式:
1 | synchronized(同步锁(锁对象)){ |
- 同步方法
格式:
1 | 修饰符 synchronized 返回值类型 参数名(参数列表){ |
- Lock锁
Lock接口中的方法:
void lock() 获取锁
void unlock() 释放锁
1 | 实例 |
3.3 线程池
线程池: 其实就是一个容纳多个线程的容器,其中的线程可以反复使用,省去了频繁创建线程对象的操作。
3.4 锁
3.5 并发容器
3.6 原子类
3.7 juc并发工具类
4. 网络编程
软件结构:c/s,b/s
4.1 网络通信
网络通信协议的分类
- UDP:用户数据报协议
特点:消耗资源小,通信效率高
通常用于音频、视频和普通数据的传输例如视频会议都使用udp协议,即使丢一两个数据包,也不会对接受结果产生太大影响。
- TCP:传输控制协议
是面向连接的通信协议。在TCP连接中必须要明确客户端与服务器端,每次连接的创建都需要经过“三次握手”。
特点:传输安全
网络编程的三要素
- 协议
- IP地址
- IPv4:32位的二进制数,通常被分为4个字节,表示a.b.c.d的形式,每个字节的范围都是0~255.
- IPv6:
- 端口号
4.2 函数式接口
函数式接口:只有一个抽象方法的接口,称之为函数式接口
当然接口中可以包含其他的方法(默认,静态,私有)
Lambda表达式
函数式编程思想:
只要能获取到结果,谁去做,怎么做的都不重要,重视的是结果,不重视过程。
使用前提
- 使用Lambda必须具有接口,且要求接口中有且只有一个抽象方法。
- 使用Lambda必须具有上下文推断
有些场景的代码执行后结果不一定被使用,从而造成性能浪费。而Lambda表达式是延迟执行的,正好可以作为解决方案,提升性能。
常用函数式接口
- Supplier接口
1 | Supplier:被称为生产型接口,指定接口的泛型是什么类型,那么接口中的get方法就会生产什么类型的数据 |
- Consumer接口
1 | Consumer:消费型接口,泛型执行什么类型,就可以使用accept方法使用什么类型的数据 |
- Predicate接口
1 | 对某种类型的数据进行判断,从而得到一个Boolean值结果。 |
4.3 Stream流
IO流和Stream流是两个概念,IO流是用于数据的读写,而Stream流可以用来对集合和数组进行简化操作。